

Für Webanwendungen bietet sich die Nutzung eines Filters an, der die Ausführungzeit des Requests messen und loggen kann.
Servlet-Filter können genutzt werden um auf die Werte eines Requests (und auch der Response) zurückzugreifen, diese zu manipulieren und weitere Aktionen durchzuführen. Durch Mappingregeln innerhalb der Deploymentdeskriptoren werden die Filter definiert und in ihrer Reihenfolge festgelegt.
In der Literatur dient in vielen Fällen das Messen der Ausführungszeit als Beispiel für die Implementierung eines Filters. Dabei können Ausführungszeiten, Zugriffszeiten auf Ressourcen oder weitere Flaschenhälse einer Anwendung geprüft werden.
Als Basis für das Beispiel wird eine per Maven erzeugte Beispielanwendung verwendet, die mit einem Filter zur statistischen Auswertung erweitert wird. Um die Komplexität des Beispiels nicht zu hoch zu setzen, wird eine Erstellung durch die Auswahl des entsprechenden Archetypes durchgeführt.

Danach steht eine rudimentäre Webanwendung mit einer einfachen "Hello World" Seite zur Verfügung. Damit diese gestartet werden kann, wird das Tomcat Plugin genutzt. Dieses muss in der pom.xml des Projektes hinzugefügt werden.

Danach sollte der Server ohne weitere Probleme durch das Goal tomcat:run gestartet und die Webanwendung aufgerufen werden können.
Vor der Implementierung des Filters sollte klar sein, wie Filter im Allgemeinen funktionieren. Die drei wesentlichen Klassen sind
Die FilterConfig ist der Teil, der sich innerhalb des Deployment Deskriptors wiederfindet und dort die Details eines Filters konfiguriert. Dabei werden die angegeben Einträge in einem Objekt vom Typ FilterConfig gekapselt und innerhalb der init Methode eines Filters zur Verfügung gestellt.
Die FilterChain ist die Kette der Filter, die durch das Framework abgearbeitet werden. Alle Filter zusammen bilden die Filterkette. In dem Interface FilterChain ist als einzige Methode die Methode doFilter(..) definiert, die für die weitere Verarbeitung der Filter verantwortlich ist. Mit Hilfe der Methode wird das nächste Element (Filter oder, falls kein Filter mehr vorhanden ist, die Ressource selbst) angesprochen.
Das Interface Filter ist das wesentliche Interface bei der Eigenentwicklung eines Filters. Jeder Filter muss das Interface implementieren, damit dieser innerhalb der Chain verarbeitet werden kann. Die verschiedenen Methoden bieten die Möglichkeit zur Interaktion mit dem Request oder auch der Response.
Der Filter für das statistische Loggen der Dauer eines Requests ist einfach gehalten um so wenig Overhead wie möglich zu produzieren. Für die Bereitsstellung der Logs wurden zwei Logger über die SLF4J Factory initialisiert und stehen im weiteren Verlauf zur Verfügung.

Die Wahl fiel an dieser Stelle bewusst auf zwei Logger, da diese unabhängig voneinander loggen können. Einmal wird auf die Konsole geloggt, so dass der Entwickler weiterhin einen guten Überblick über die Meldungen hat und zum anderen wird über einen RollingFileAppender statistische Daten in eine Datei geloggt, so dass diese später weiterverarbeitet werden können. Das Konfigurationsfile ist wie folgt aufgebaut:
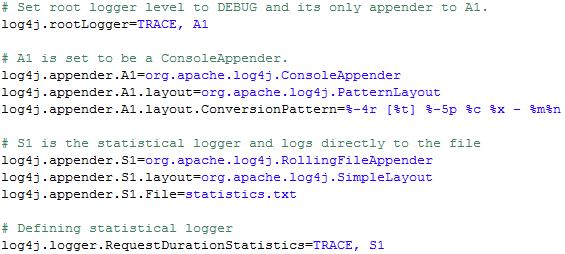
Die Implementierung der Methode gestaltet sich ebenfalls nicht weiter schwierig, so dass auf größere Erklärungen verzichtet werden kann.

Im weiteren Schritt braucht der Filter nur noch in den Deployment Deskriptor eingetragen werden. Dafür werden in der web.xml das Filtermapping und auch der Filter an sich ergänzt. Für die Namensgebung und die Verweise innerhalb der web.xml gelten die gleichen Regeln, wie für das definieren von Servlets und Servletmappings.
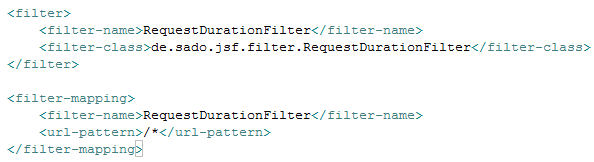
Wichtig an dieser Stelle ist, dass die Reihenfolge durch die Einträge innerhalb des Deployment-Deskriptors definiert werden. Für die Bestimmung der Filterreihenfolge existieren zwei wesentliche Kriterien. Zum einen gilt, dass Filter, die mit einem URL Mapping definiert worden sind immer Vorrang vor den Filtern mit einem Servletmapping haben. In der jeweiligen Gruppe der Filter entscheidet dann, als zweites Kriterium, die Reihenfolge der Definitionen.
Sobald der Filter aktiviert ist und die Anwendung erneut gestartet wurde, können die Ausgaben auf der Konsole, als auch innerhalb der Datei gefunden werden.

Die statistische Auswertung kann dann anhand der Textdatei erfolgen. Dort hilft ein Import und eine Betrachtung mit Hilfe von Excel um die Ergebnisse grafisch auszuwerten.

Wobei an dieser Stelle noch mehr herauszuholen ist ;-)
Das gesamte Projekt ist wie gewohnt bei Cloudbees im Repository zu finden.
Keine Kommentare:
Kommentar veröffentlichen