Collections, und auch Maps, von einfachen Datentypen können direkt und somit ohne weitere Entitäten gemappt werden. Nahezu alle Konfigurationsmöglichkeiten bleiben dabei erhalten. Ein paar Feinheiten und Besonderheiten sind allerdings zu beachten.
Für die Beispiele wird die JPA Spec (JSR-317) zu Grunde gelegt.
java.util.List<T> / java.util.Set<T>
In JSR-317 ist definiert, dass alle Collections von einfachen Datentypen, wie auch von sogenannten Embeddables, durch eine einfache Annotation gemappt werden können. Ein einfaches Beispiel ist für diesen Fall schnell erstellt.

Die zentrale Annotation ist in diesem Fall @ElementCollection zur Definition einer Liste von Vornamen. Somit ist keine weitere Entität notwendig, die einen Wrapper um den einfachen Vornamen bildet, wie es vorher notwendig war. Entsprechende Tabellen werden automatisiert erstellt.
In diesem Fall wird die Beziehung direkt über eine Foreign-Key-Relation in der Tabelle Person_firstnames abgebildet. Auf den ersten Blick wäre eine sprechendere Tabellenbezeichnung sinnvoller. Daher wird die Entität durch eine Annotation erweitert:

@CollectionTable bietet die Standardkonfigurationsoptionen, wie:
- name
- schema
- catalog
- joinColumns
- uniqueConstraints.
Weitere Konfigurationen sind nicht notwendig und wie zu sehen ist, wird das Mapping für einfache Datentypen deutlich einfacher.
@ElementCollection kann aber nicht nur auf einfache Datentypen, sondern auch auf Embeddables angewandt werden. Ein Embeddable ist eine Klasse, die innerhalb der beinhaltenden Entität gespeichert wird und sich die Id mit der beinhaltenden Klasse teilt. Dabei wird jedes persistente Attribut / Embeddable mit persistiert.

Mit der Erweiterung durch die Liste der favorisierten Gerichte, werden die generierten Tabellen ebenfalls umfangreicher.

Wie zu sehen ist, wird aus dem FavoriteFood keine separate Entität, sondern, wie auch bei den Vornamen, eine einfache Liste, verknüpft über eine normale Fremdschlüsselbeziehung.
In beiden Fällen, sowohl bei den einfachen Datentypen, als auch bei den Embeddables, ist allerdings wichtig, dass mit dem Interface java.util.List gearbeitet wird und nicht mit einer konkreten Implementierung. Wird nicht mit dem Interface gearbeitet, tritt bereits einer Fehler bei der Analyse durch dem OR-Mapper auf.

Ein Grund für eine konkrete Implementierung wäre als Beispiel das Sortieren. Das kann an dieser Stelle eleganter gelöst werden.
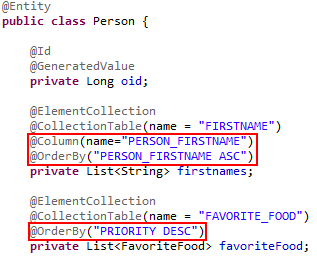
Mit Hilfe der Annotation @OrderBy kann sowohl die Spalte nach der sortiert werden soll, als auch die Reihenfolge (asc oder desc) definiert werden. @OrderBy sorgt für eine Erweiterung der Statements um eine "ORDER BY" Bedingung auf die angegebene Spalte.
Spannend ist auch die Speicherung einer Liste von Enums. Wie beim Speichern von Enum-Werten, kann auch für die gesamte Liste angegeben werden, ob der Ordinalwert oder die textuelle Darstellung gespeichert werden kann.

java.util.Map<K,V>
Für die Benutzung von Map gelten im wesentlichen die gleichen Regeln, wie auch für das Nutzen von Set oder List. Somit wird der Einsatz von Maps in Entitäten leichter als er es vormals war. Eine Map mit einfachen Werten wird, wie auch Listen oder Sets, leicht gemappt, daher steige ich auch hier direkt mit einem etwas komplexeren Beispiel ein. Die Liste der Haustiere wird ersetzt durch eine Map der Haustiere mit ihren zugehörigen Namen.

Die Tabellenstruktur wird entsprechend um eine Tabelle erweitert.

Dabei ist zu erkennen, dass die neu erstellte Tabelle Person_pets neben dem Fremdschlüssel zur Person zwei weitere Spalten beinhaltet. Die eine Spalte pets_KEY entspricht dem Schlüssel der Map (dem Namen des Haustieres) und die Spalte pets entspricht dem Wert in der Map. Sofort fällt auf, dass neben dem nicht unbedingt glücklichem Namen der Tabelle auch nicht unbedingt der Ordinalwert der Enum gespeichert werden soll. Auch dies kann durch Annotationen behoben werden.

Mit @Enumerated wird festgelegt, dass der Wert des Eintrages in der Map als textuelle Repräsentation gespeichert wird. Gleichzeitig können mit Hilfe der Annotation @MapKeyColumn die Eigenschaften der Schlüsselspalte festgelegt werden. Sollen die Eigenschaften der Wert-Spalte festgelegt werden, wird dafür die normale @Column Annotation verwendet.
Was ist aber, wenn die Schlüsselspalte der Map als Enum werden soll?

Mit der Annotation @MapKeyEnumerated kann die Art der Speicherung für den Enum-Wert in der Schlüsselspalte festgelegt werden. Somit besteht auch an dieser Stelle die Möglichkeit, dass nicht der Ordinalwert, sondern die textuelle Repräsentation gespeichert wird.
Wie also zu sehen ist, wird das Mapping von einfachen Collections mit JSR-317 deutlich leichter und komfortabler. Viel Erfolg beim Ausprobieren!
Die Beispiele finden sich wie immer im Repository.